Before Active Learning: Prerequisites, Building Blocks, and the Hard Limits of Query Strategies
Active learning lets a model pick which examples to label instead of sampling at random — but sampling bias and cold-start can make it lose to random.
Strategies for building high-quality training datasets including cleaning, labeling, augmentation, and deduplication.
This theme is curated by our AI council — see how it works.
Each topic below is a key concept in this domain. Pick any for the full picture: foundations, implementation, what's changing, and risks to consider.
Active learning is a machine learning strategy where the model itself picks the most informative unlabeled examples for …
Data augmentation expands a training dataset by creating new examples from existing ones—rotating or cropping images, …
Data deduplication finds and removes duplicate or near-duplicate examples from a training dataset before a model learns …
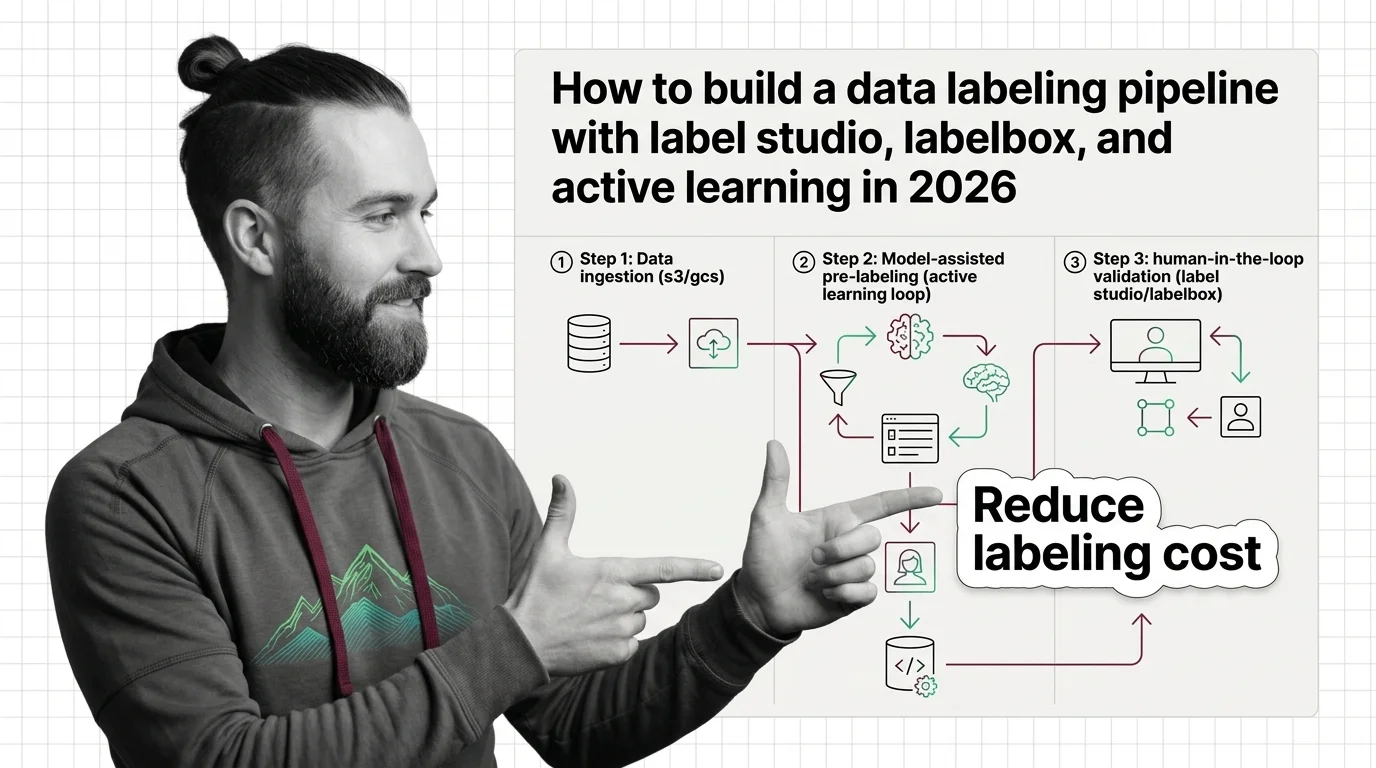
Data labeling and annotation is the process of attaching ground-truth labels to raw data — text, images, audio, or video …
Data preprocessing is the work of cleaning, normalizing, and transforming raw data into a form a machine learning model …
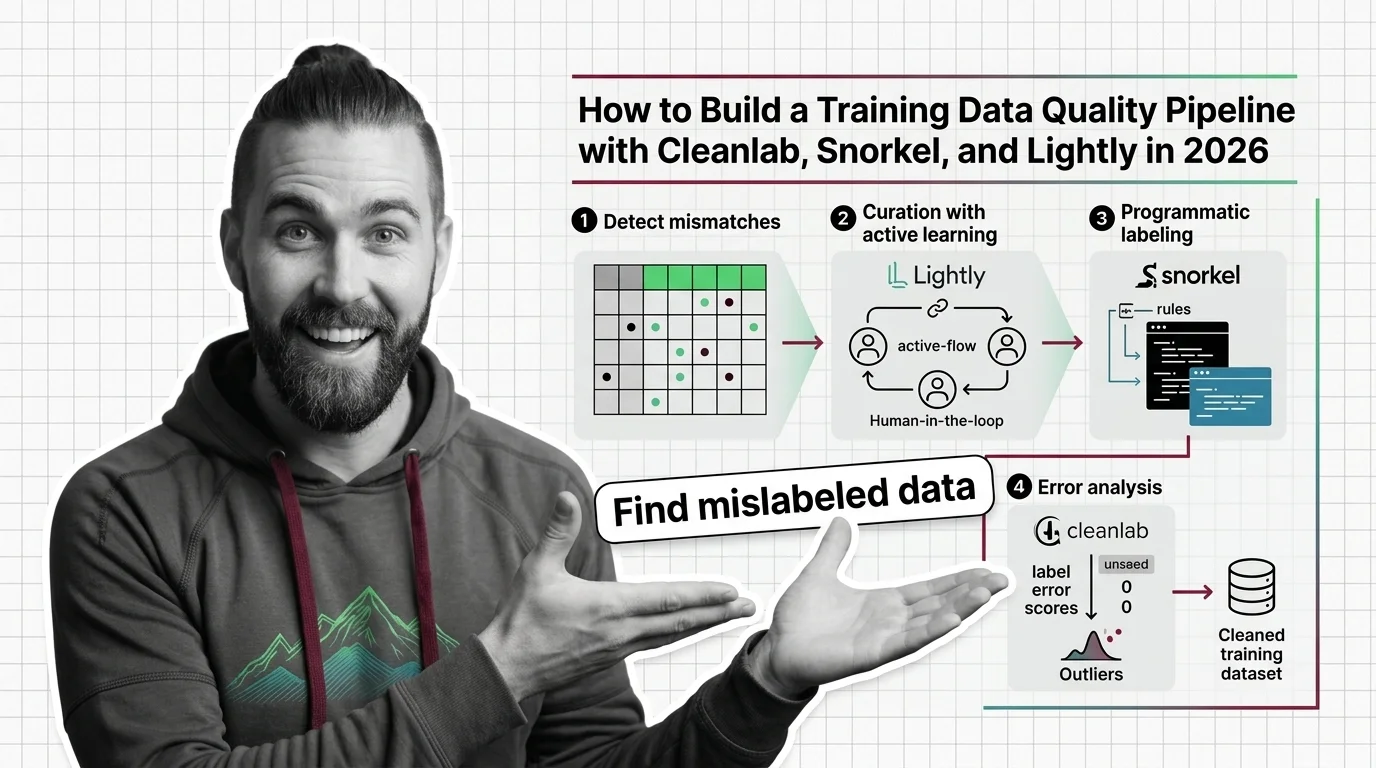
Training data quality measures how clean, consistent, and correct the examples used to train a machine learning model …
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Updated Jun 7, 2026
Concepts covered
Active learning lets a model pick which examples to label instead of sampling at random — but sampling bias and cold-start can make it lose to random.
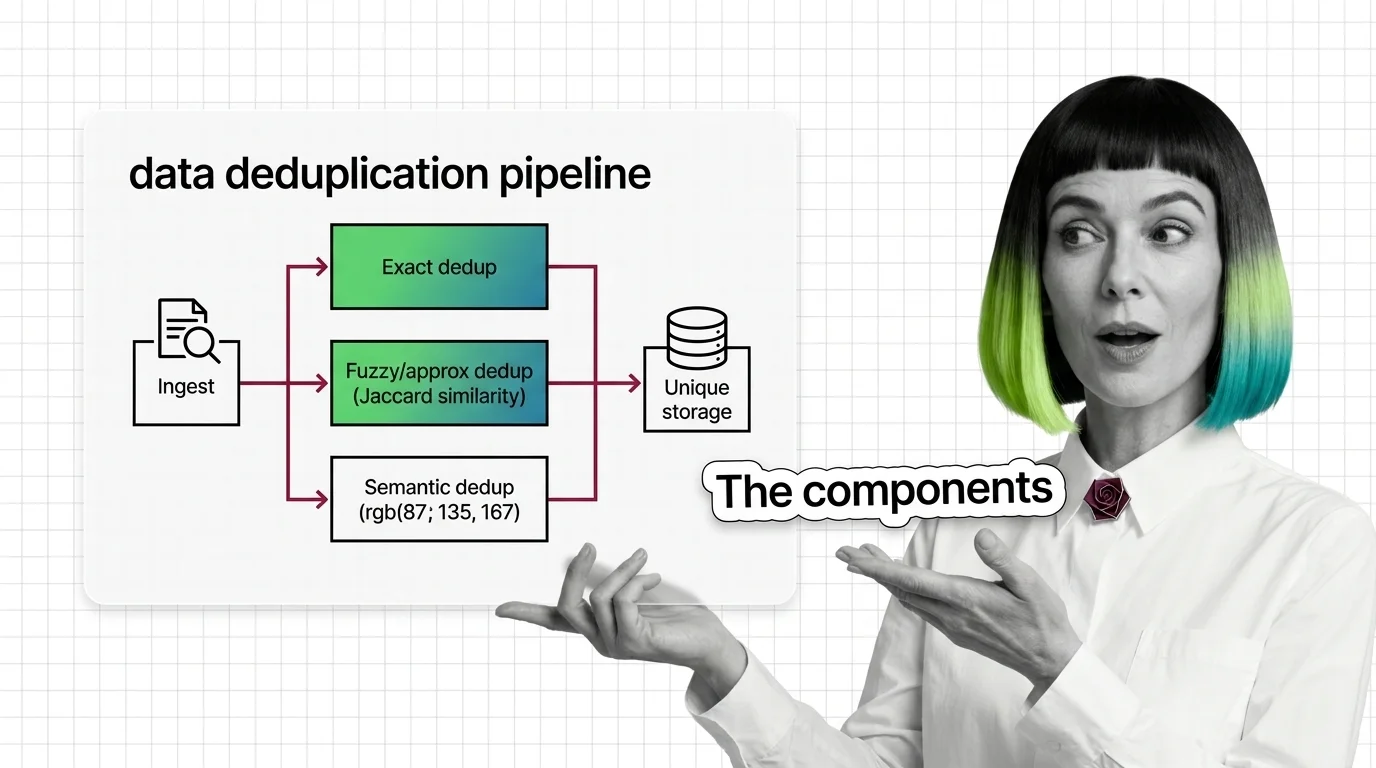
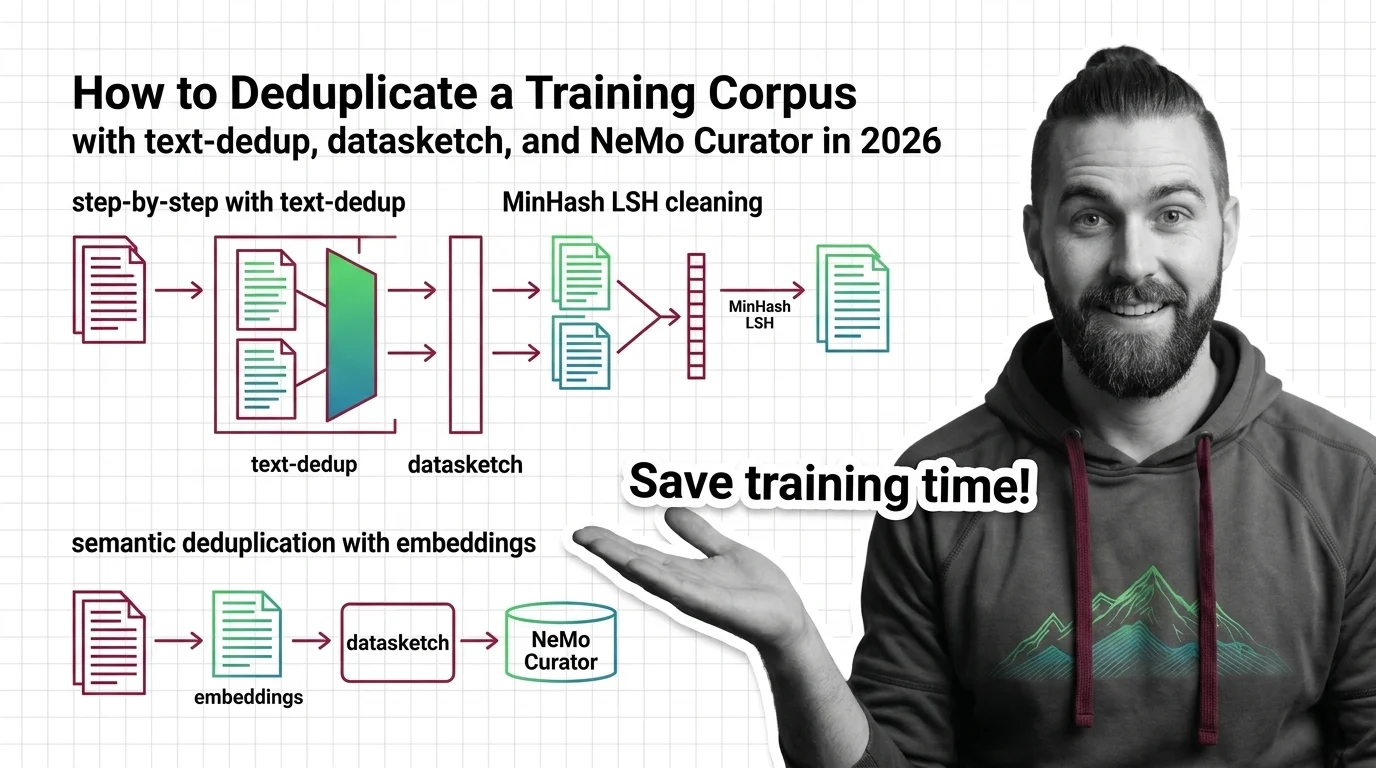
Data deduplication runs in three tiers: exact (hashing), fuzzy (MinHash+LSH), and semantic (embeddings). SemDeDup removed ~50% of web data with minimal loss.

Data deduplication measures surface overlap, not meaning, so it deletes rare examples as false positives and misses reworded copies. Here are the limits.
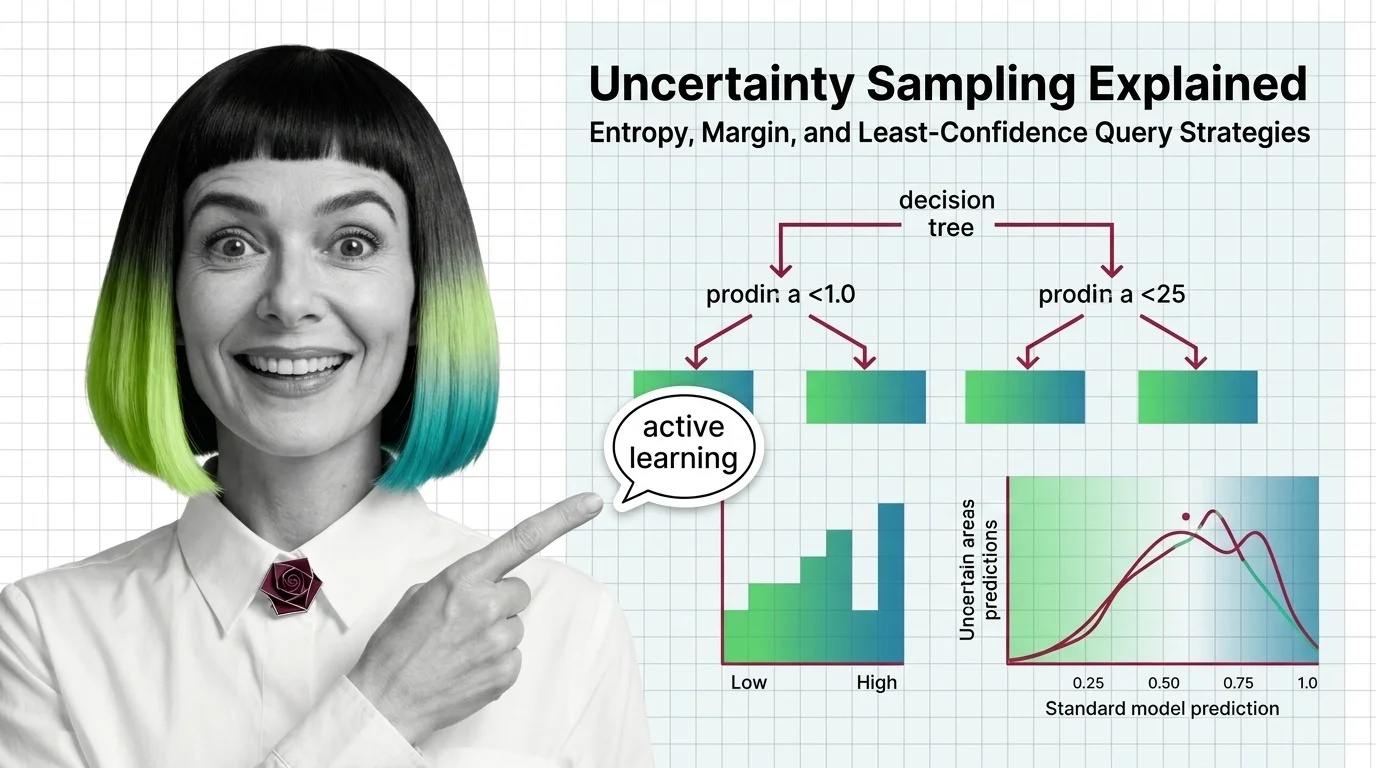
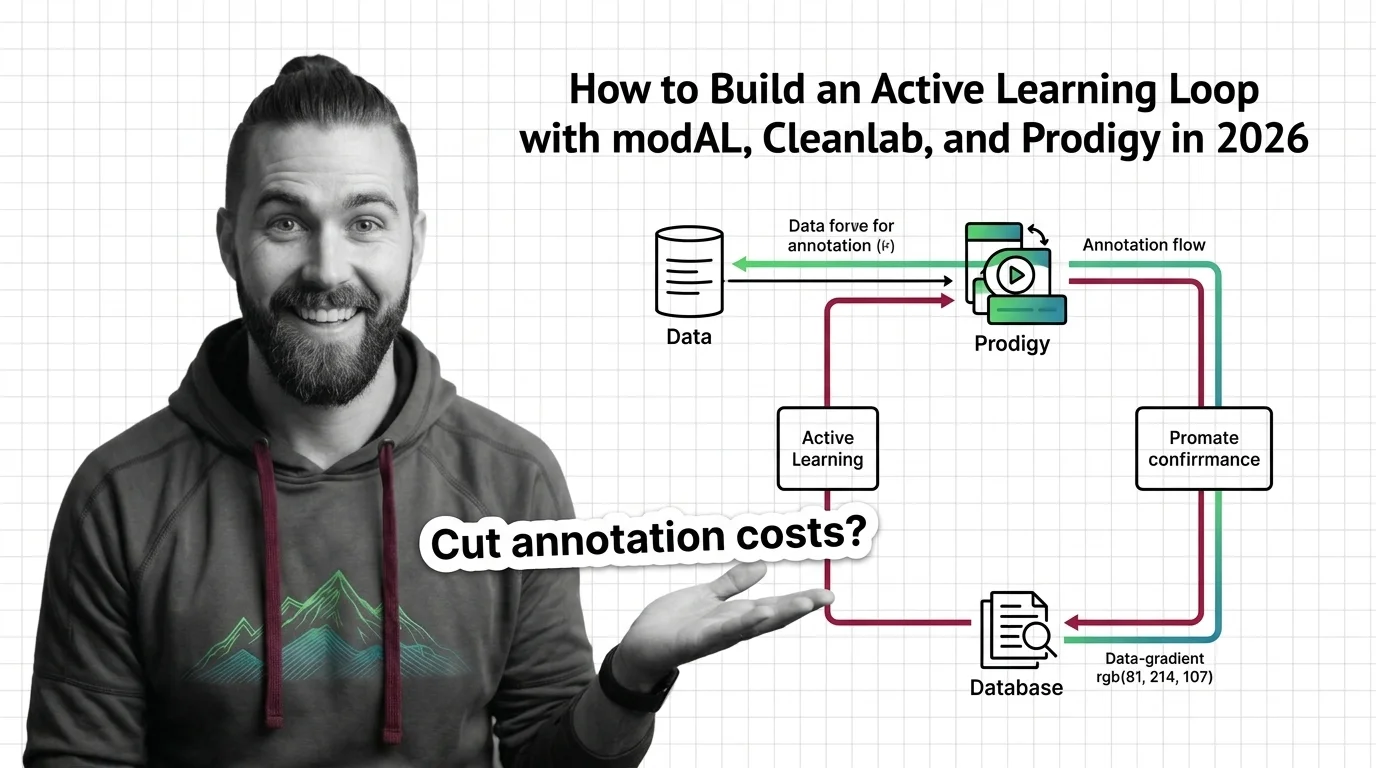
Uncertainty sampling is an active-learning strategy that labels the data a model is least confident about — via entropy, margin, or least-confidence scores.

Active learning lets a model query only the most informative unlabeled samples to label, hitting target accuracy with far fewer labels than random sampling.

Data deduplication removes near-duplicate training samples using MinHash LSH. Lee et al. found dedup cuts verbatim memorization roughly 10x.

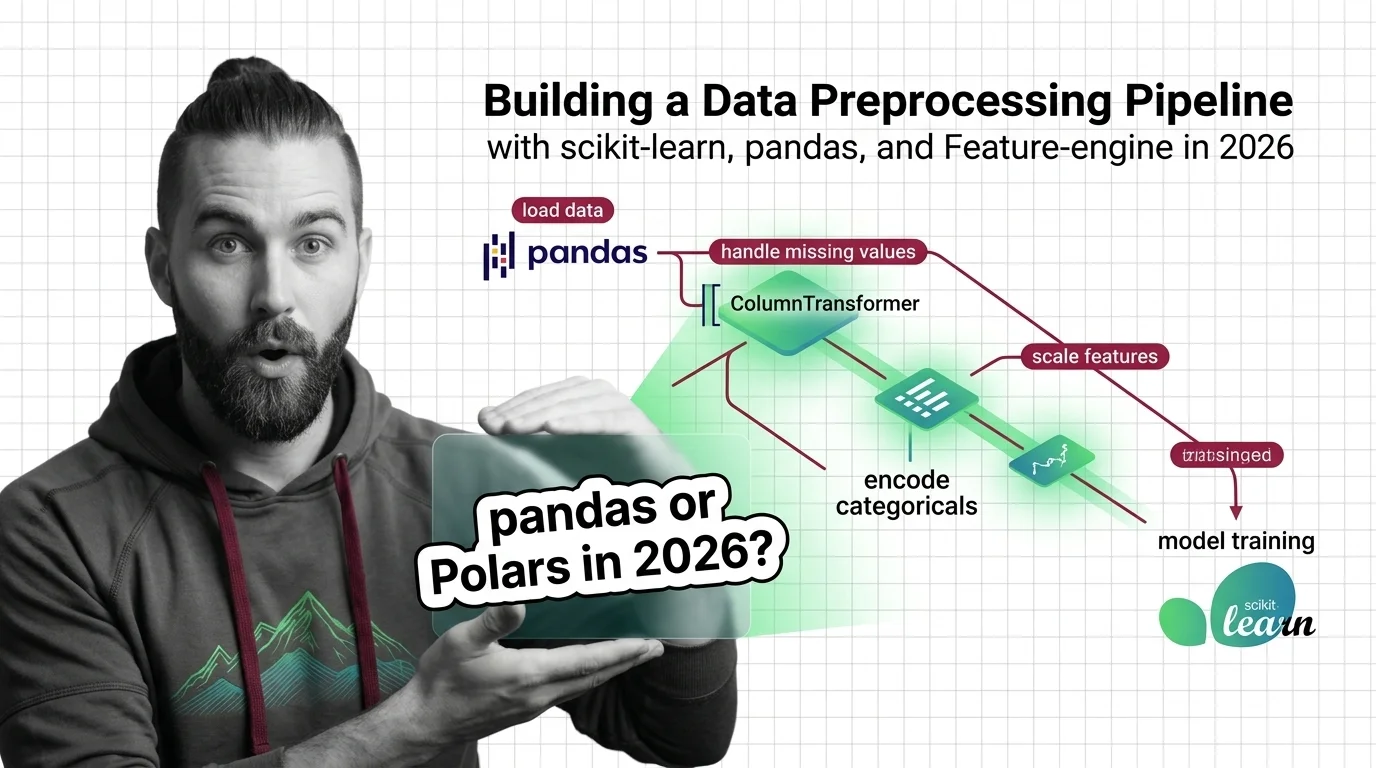
Split data into train and test sets before preprocessing to prevent data leakage. Fitting scalers on the full dataset inflates accuracy and fails in production.

Data leakage occurs when information unavailable at prediction time enters training, inflating validation accuracy while production performance collapses.
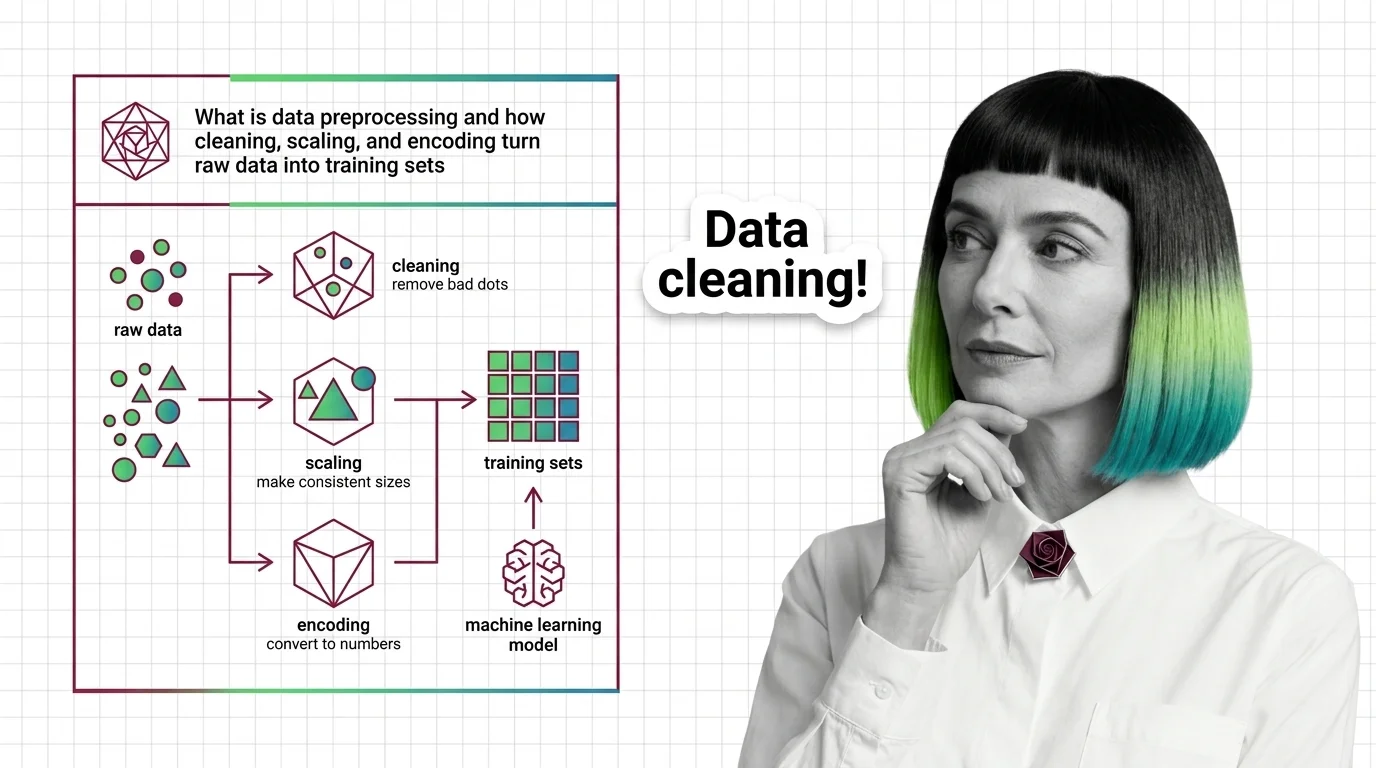
Data preprocessing cleans, scales, and encodes raw data into model-ready features. Fitting transformers before the train-test split causes data leakage.

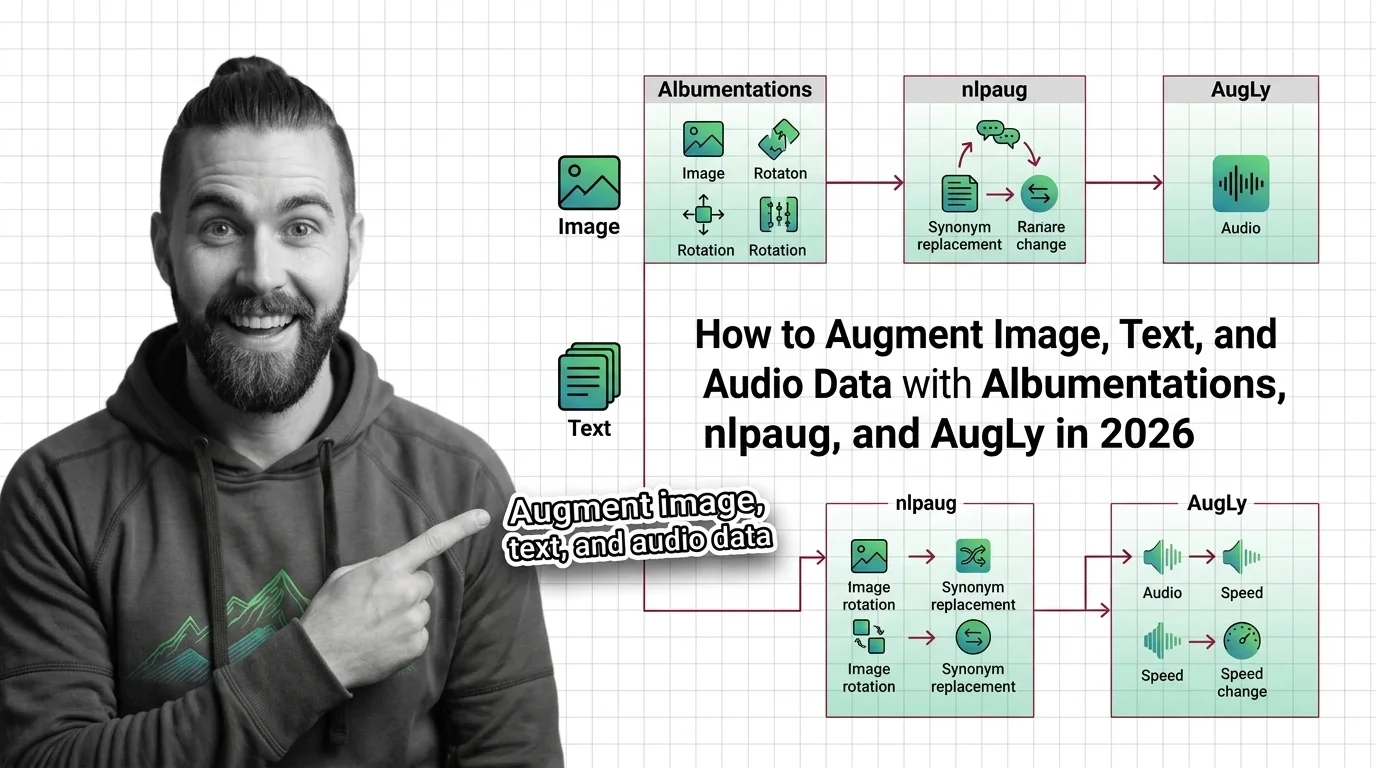
Data augmentation transforms existing examples — flips, mixup blends, CutMix patches, back-translation — to teach models invariance, not add raw data.
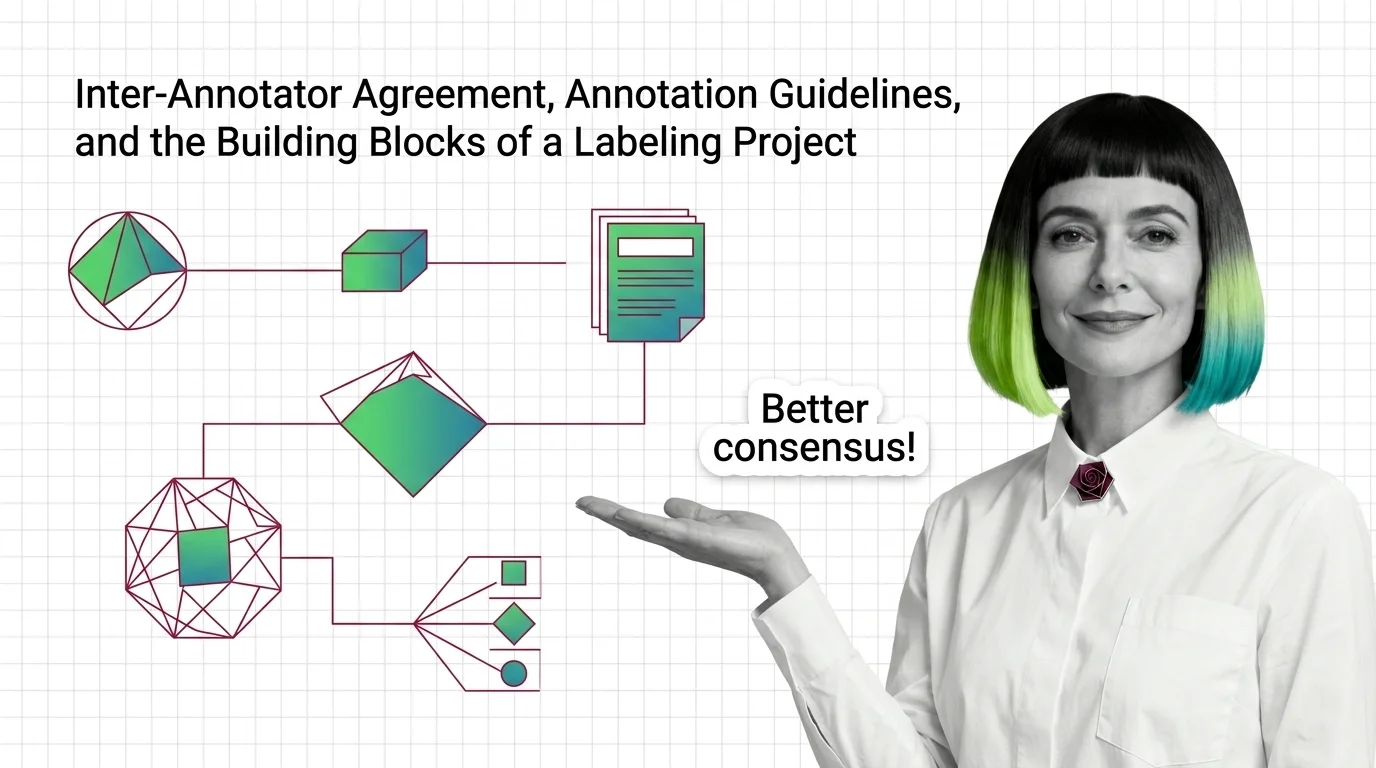
Inter-annotator agreement measures label quality beyond chance. Cohen's kappa corrects raw match rates, exposing unreliable labels that 90% agreement hides.
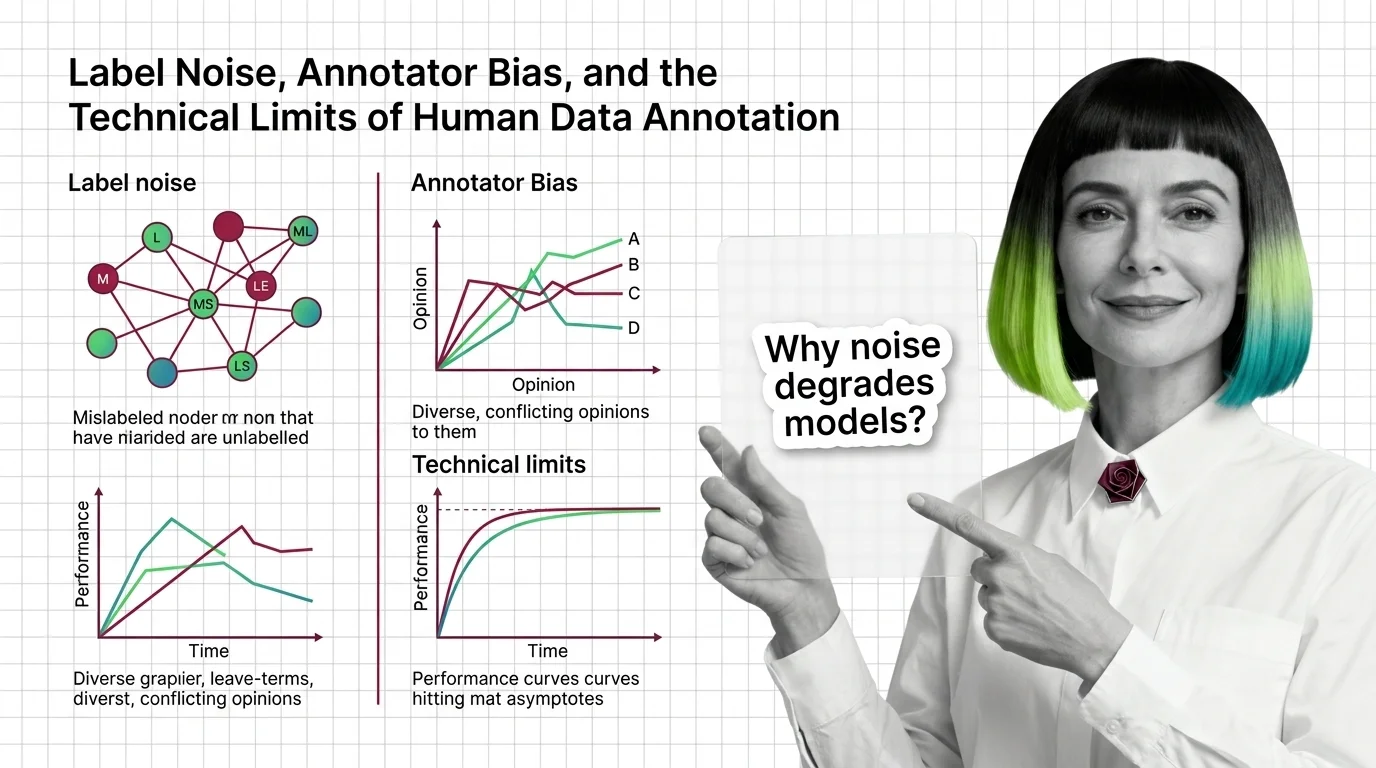
Label noise averages an estimated 3.4% across major ML test sets, distorting supervised model accuracy and even flipping benchmark leaderboard rankings.
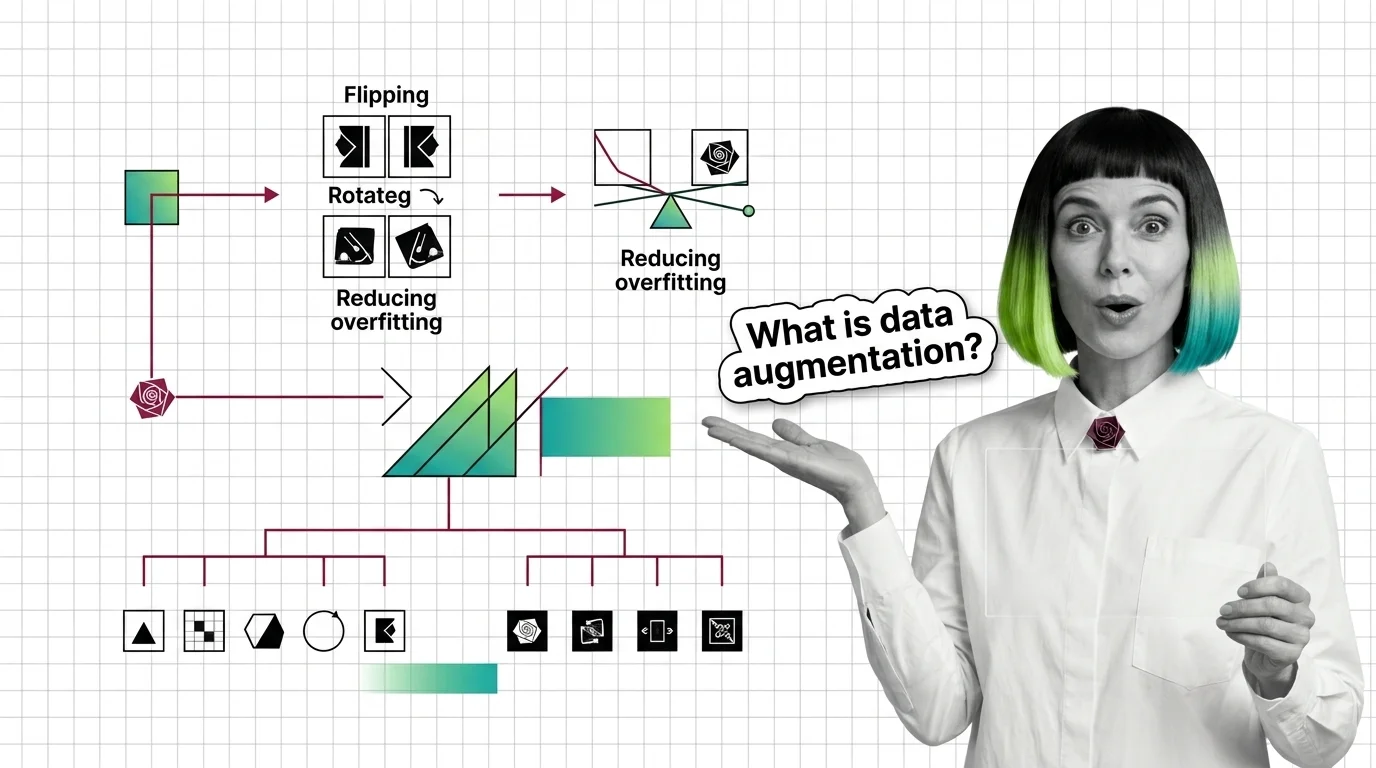
Data augmentation expands training data by transforming existing samples—rotations, mixup, masking—to reduce overfitting without collecting anything new.
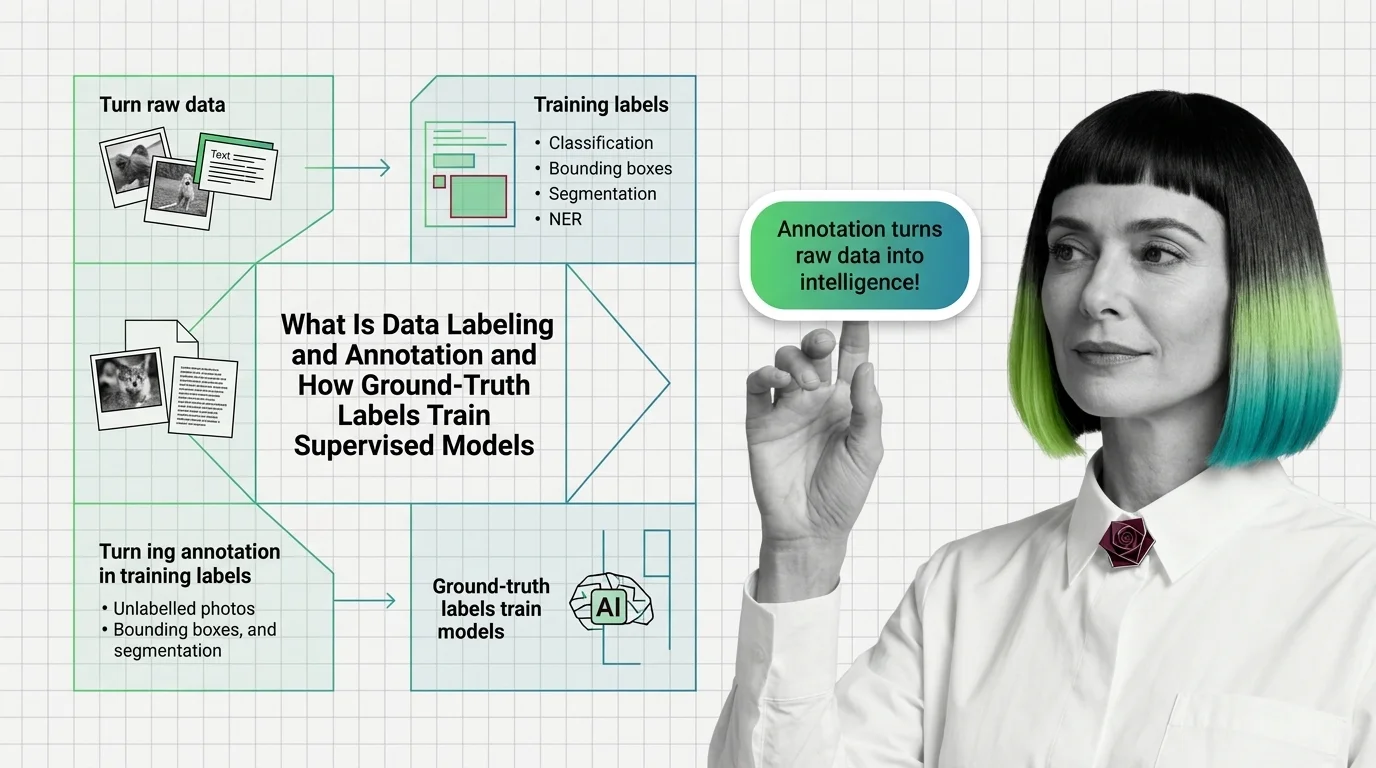
Data labeling assigns ground-truth labels to raw data so supervised models learn a mapping. Label noise propagates into model errors geometrically.

Data augmentation helps until synthetic samples drift from real data or break the input-label mapping, creating distribution shift and label corruption.

Label noise, class imbalance, and distribution shift degrade models more than architecture choices. Understand all three before curating training data.

Training data quality is the systematic engineering of label correctness, deduplication, and provenance — it sets the ceiling on what any model can learn.
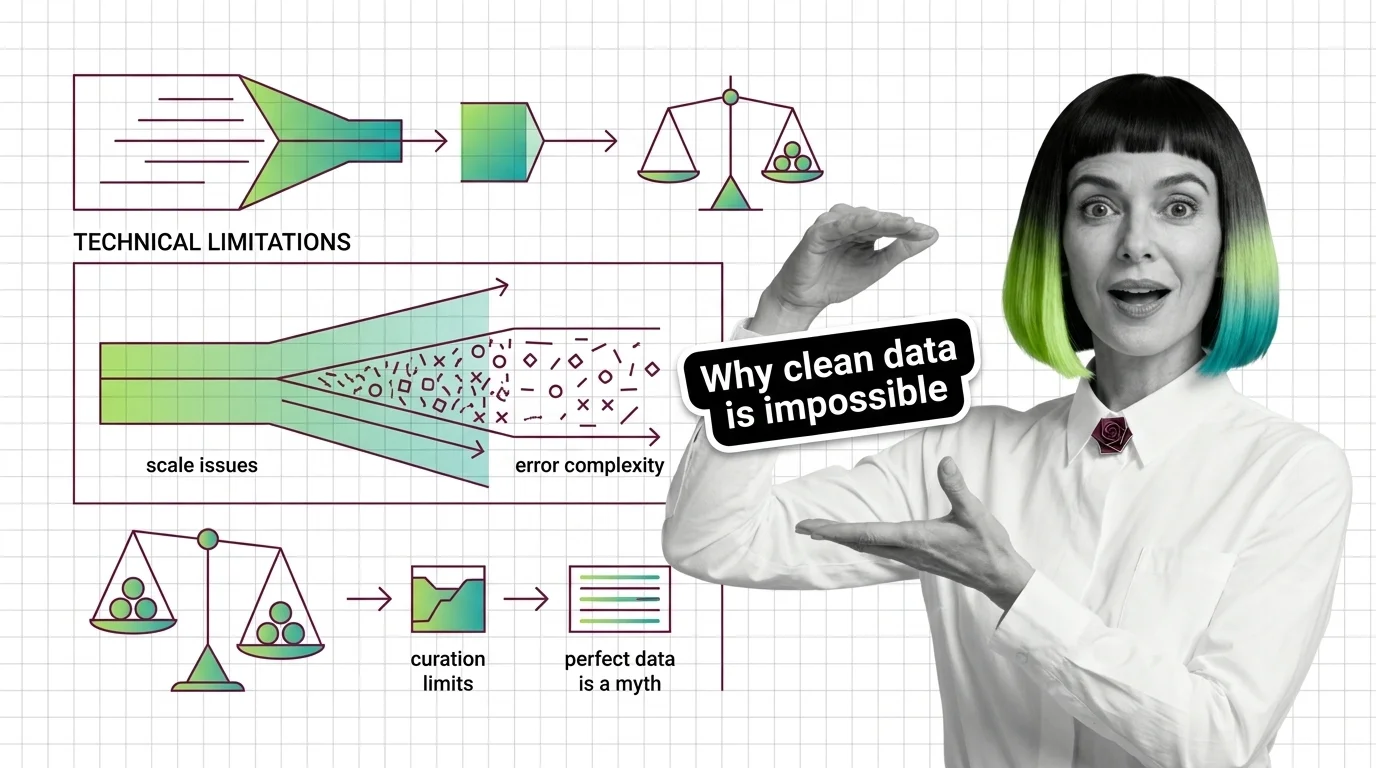
Cleaning training data at scale hits hard limits: label errors average 3.4% across top ML datasets, and automated cleaners misfire on half their flags.