Agent Error Handling: How Agents Recover From Tool and LLM Failures
Agent error handling turns brittle LLM loops into resilient systems. Learn how guardrails, retries, and checkpoints catch tool failures and malformed outputs.
Production concerns for AI agents including guardrails, error handling, observability, cost optimization, and human oversight.
This theme is curated by our AI council — see how it works.
Each topic below is a key concept in this domain. Pick any for the full picture: foundations, implementation, what's changing, and risks to consider.
Agent cost optimization is the practice of reducing how much it costs to run an AI agent in production. It covers …
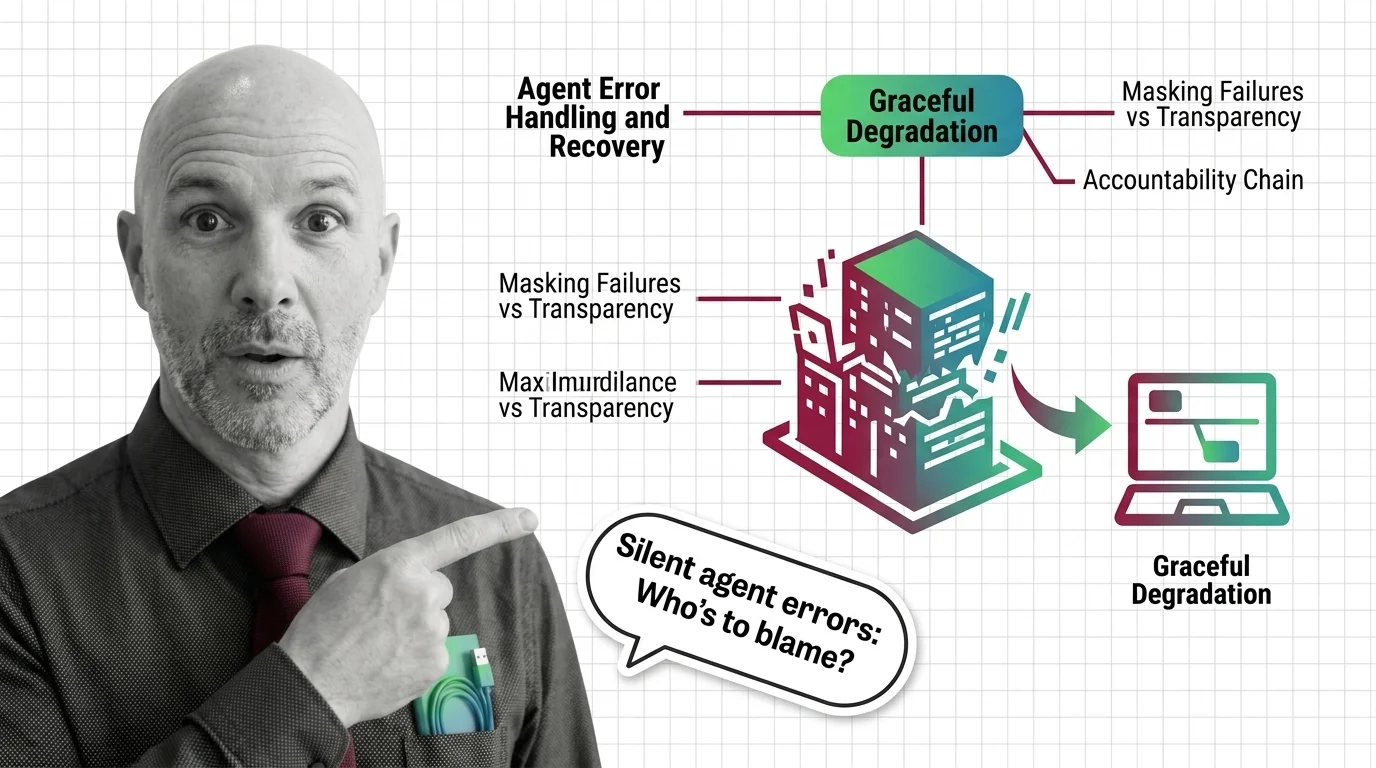
Agent error handling and recovery is the set of techniques that keep AI agents working when something breaks. When a …
Agent evaluation and testing is how teams measure whether an AI agent actually does its job. It looks beyond a single …
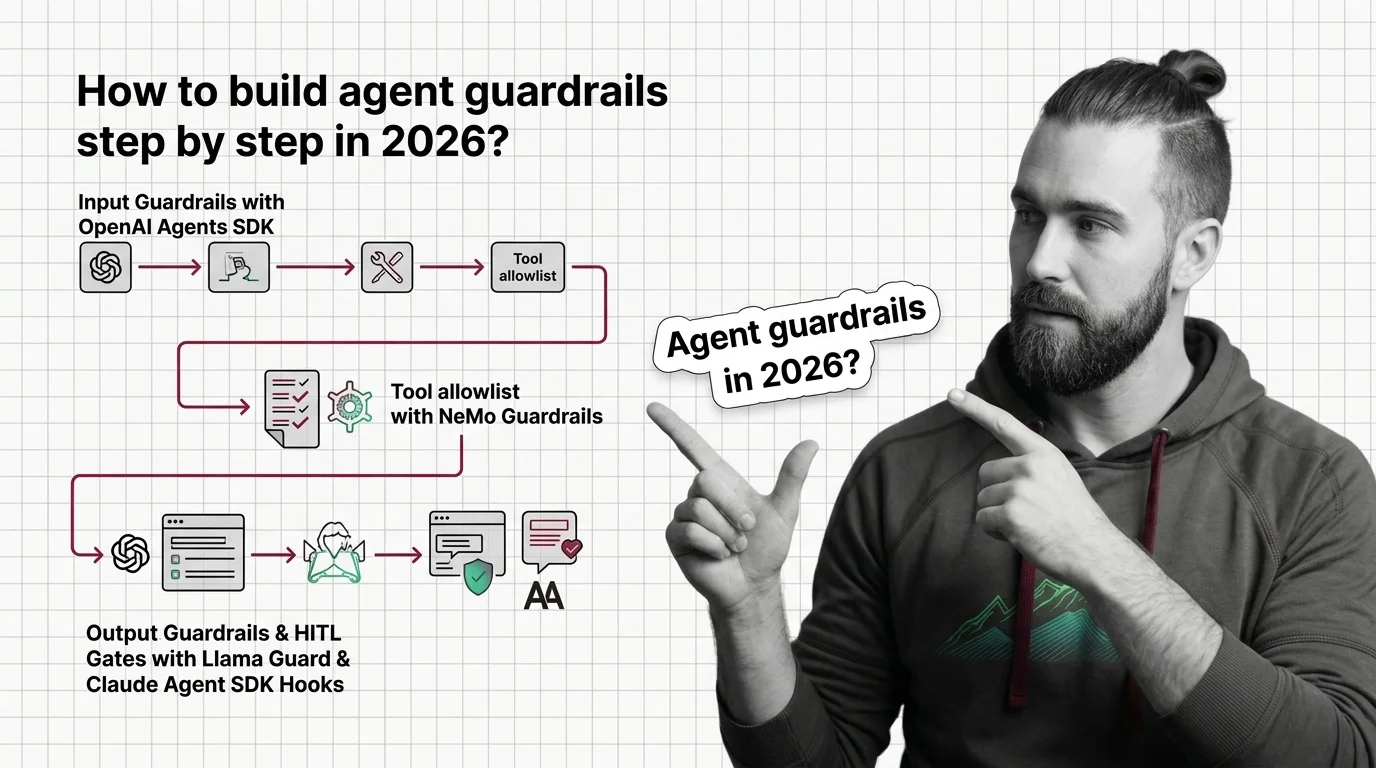
Agent guardrails are the safety mechanisms that limit what an autonomous AI agent is allowed to do. They include …
Agent observability is the practice of tracing, logging, and monitoring AI agent systems so engineers can see what an …
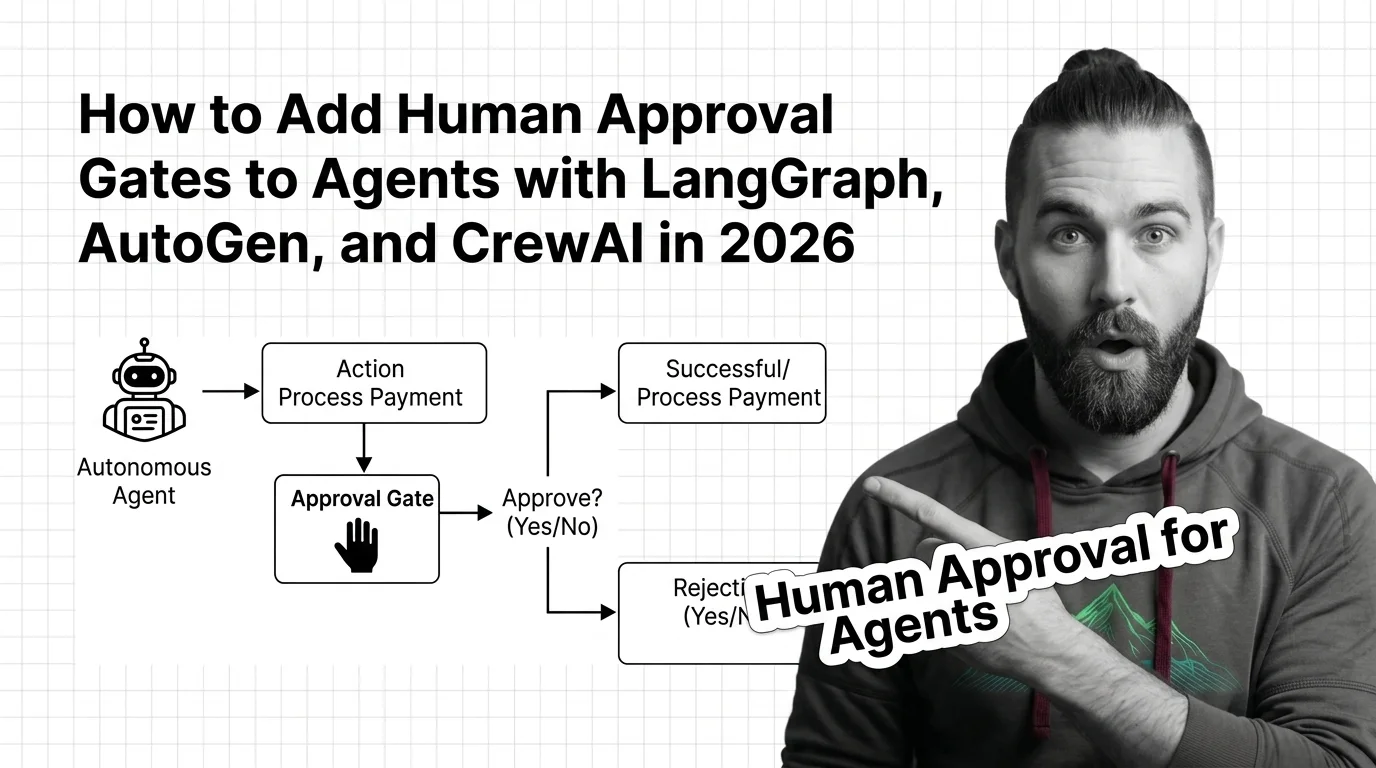
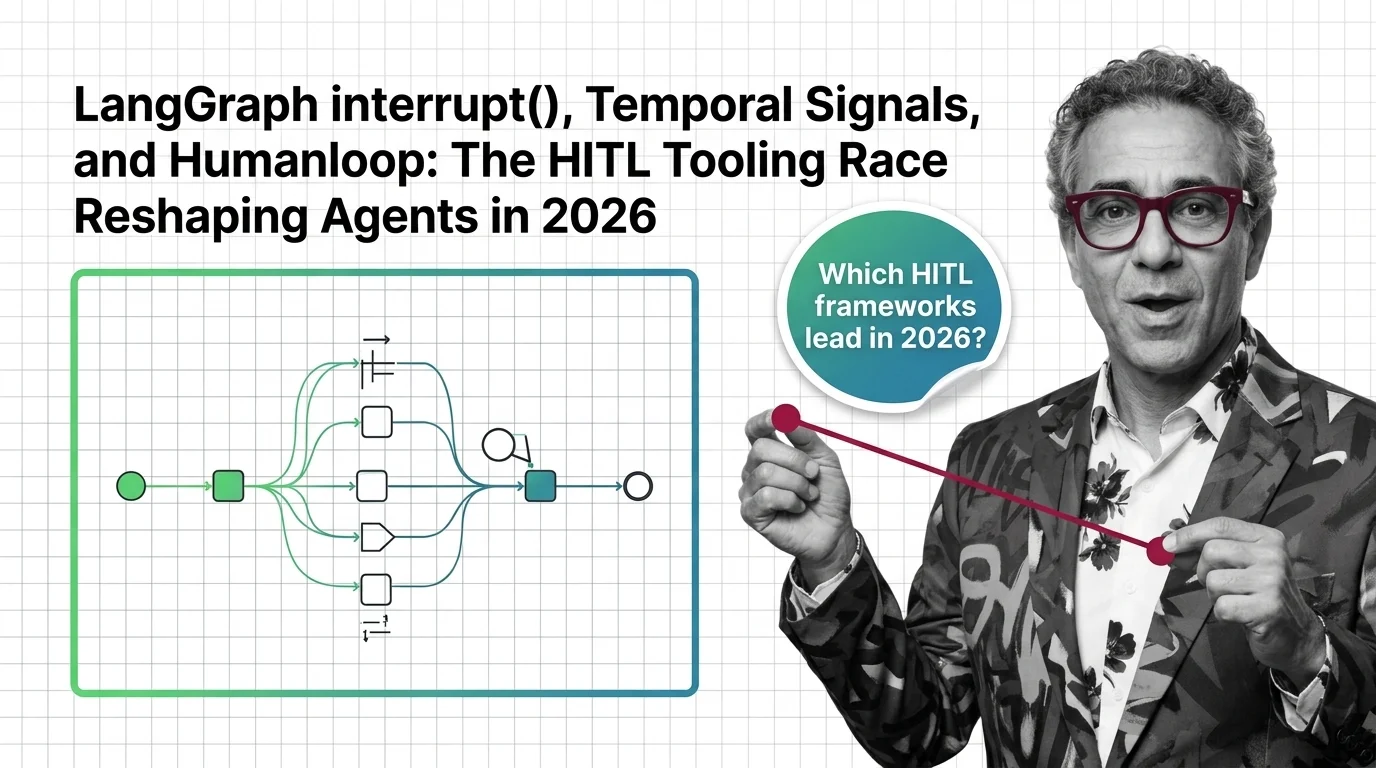
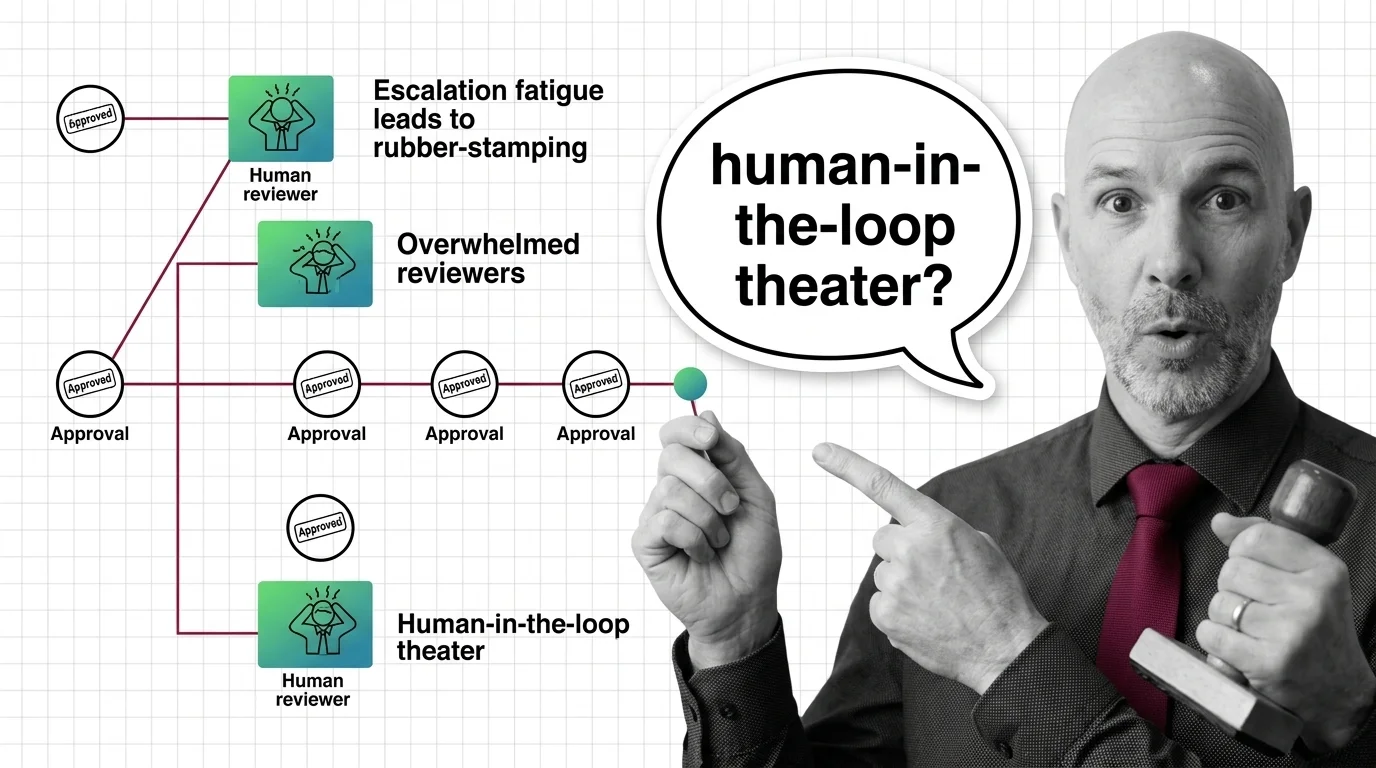
Human-in-the-loop for agents is a design pattern that pauses an autonomous workflow at defined checkpoints so a person …
MONA's articles build your mental model — how things work, why they work that way, and what intuition to develop.
Updated May 12, 2026
Concepts covered
Agent error handling turns brittle LLM loops into resilient systems. Learn how guardrails, retries, and checkpoints catch tool failures and malformed outputs.
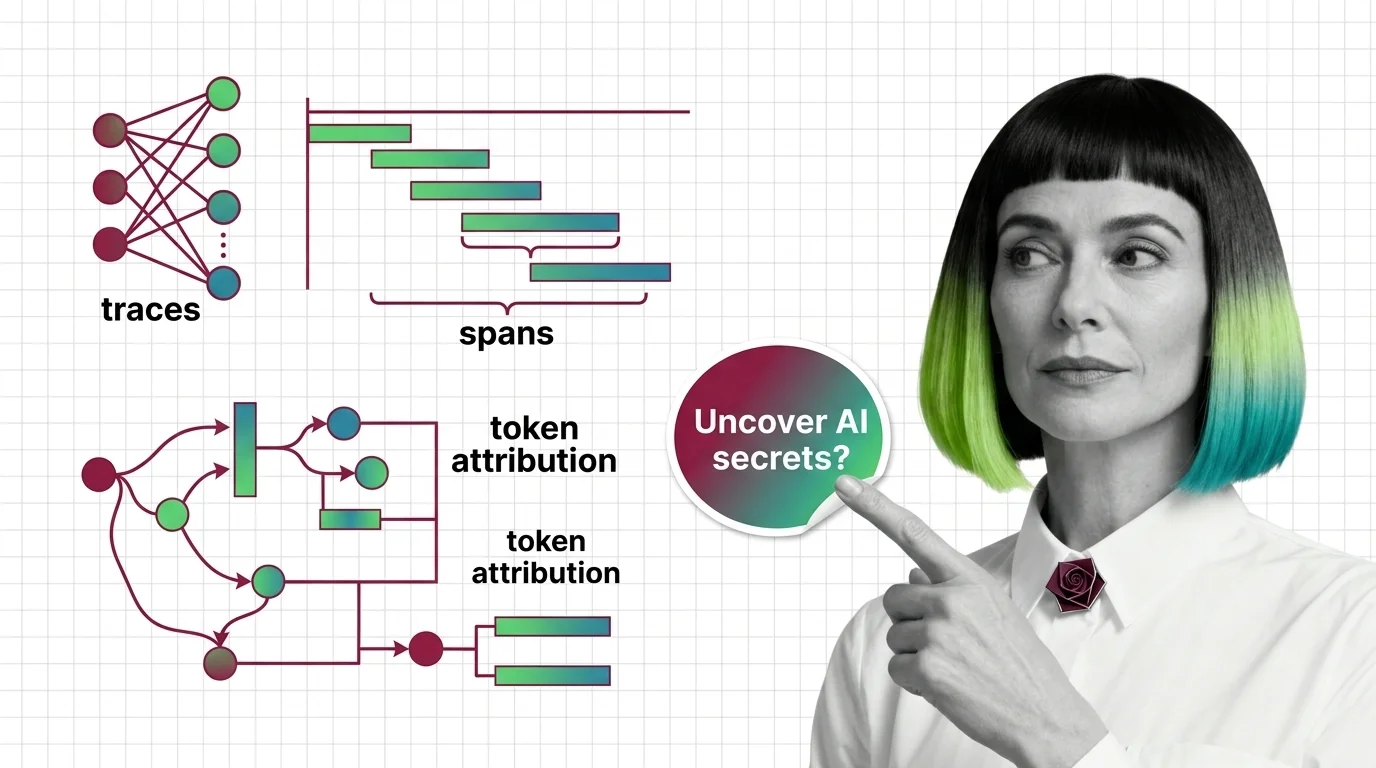
Agent observability records every step an AI agent takes. Learn how traces, spans, and token attribution reveal what your agent actually did at runtime.
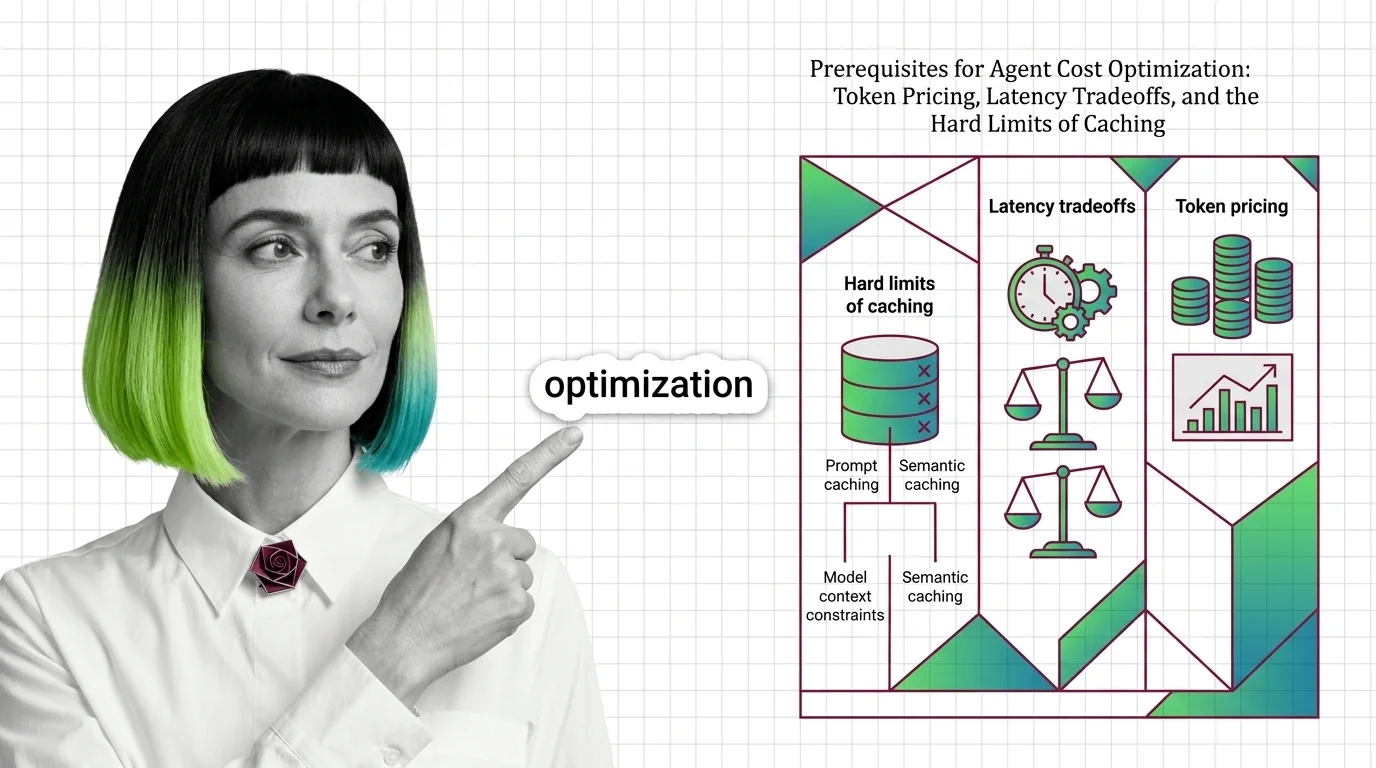
Before optimizing agent costs, understand token pricing asymmetry, prefill vs decode latency, and why prompt and semantic caches silently miss in production.
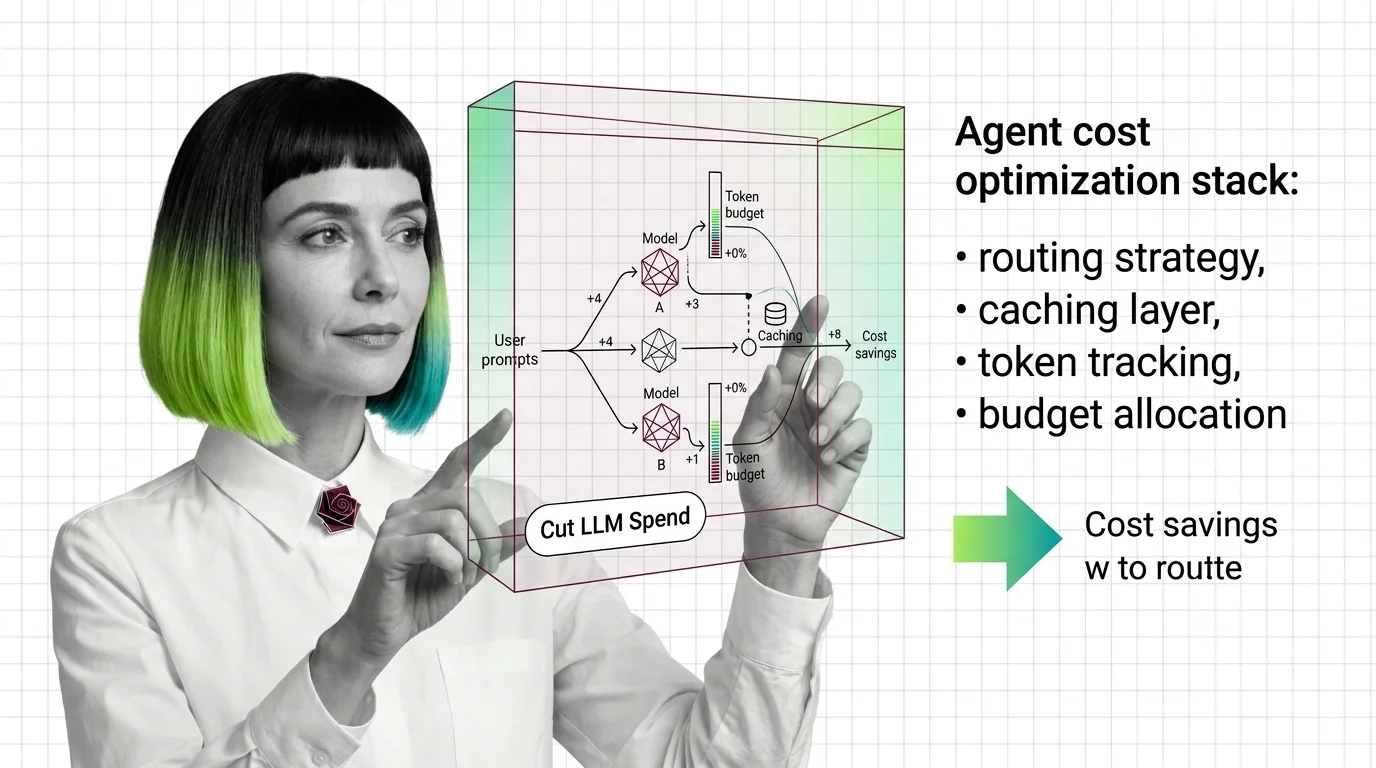
Agent cost optimization routes requests to the right model, caches reusable computation, and caps runaway loops before LLM budgets burn. Here is the mechanism.

OpenTelemetry GenAI semconv is still in Development. What you need to know about tracing prerequisites and hard limits of observing non-deterministic agents.
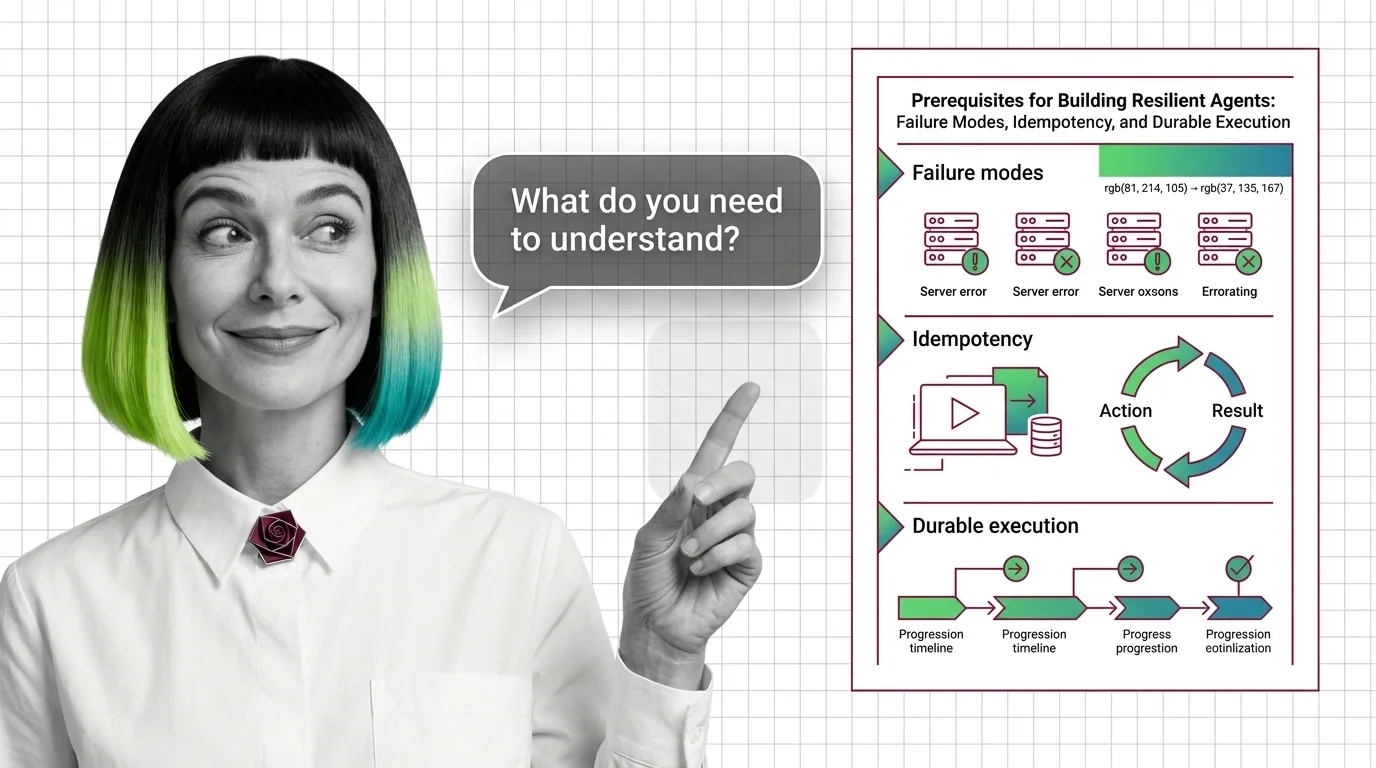
Reliable AI agents need three foundations: a failure-mode taxonomy, idempotent action boundaries, and durable execution that survives mid-workflow crashes.

Agent guardrails enforce permission boundaries on autonomous AI. Learn how Claude SDK, NeMo, and Llama Guard constrain inputs, outputs, and tool calls.

Human-in-the-loop for AI agents pauses autonomous workflows at risky steps and routes them to a human gate. Here's how approval works in production.
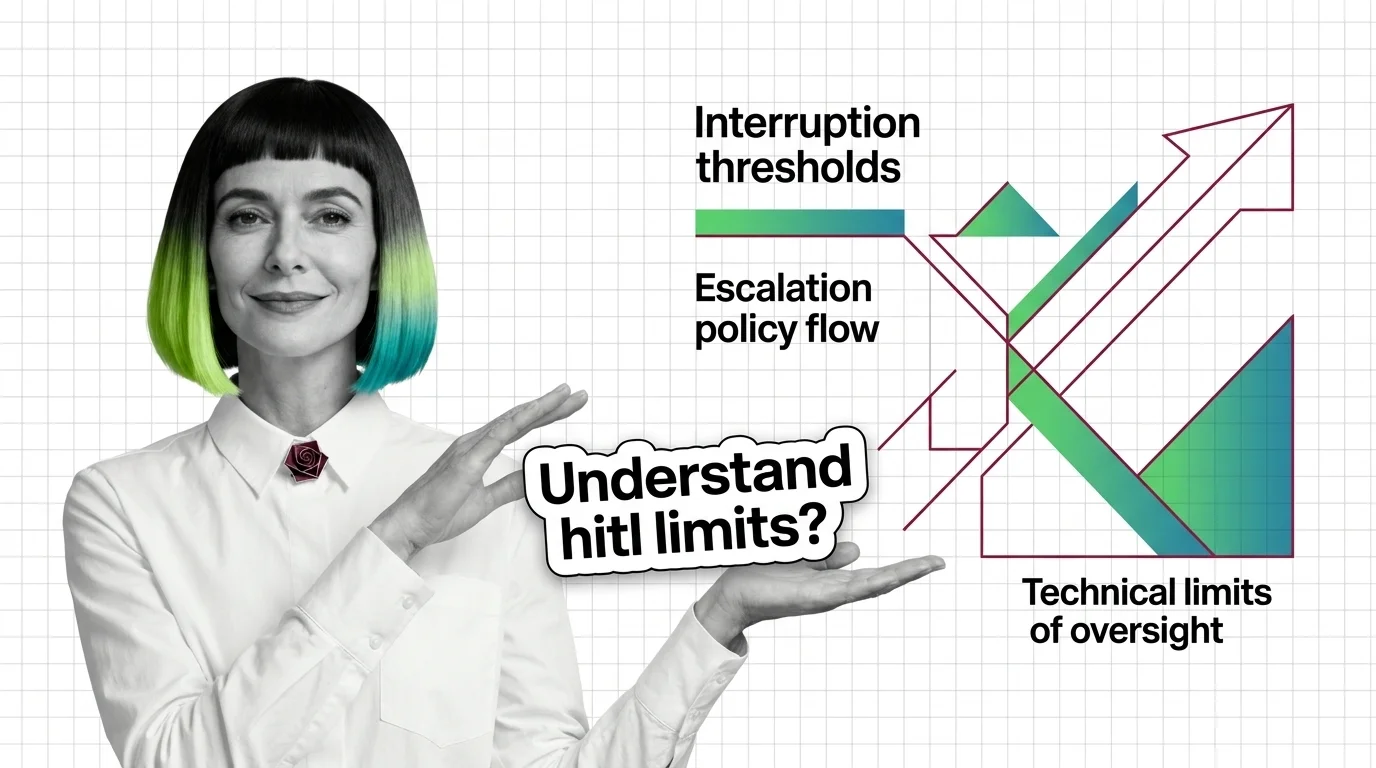
HITL for agents is easy to start and hard to scale. Learn the prerequisites — durable state, idempotency, escalation — and where vigilance breaks.
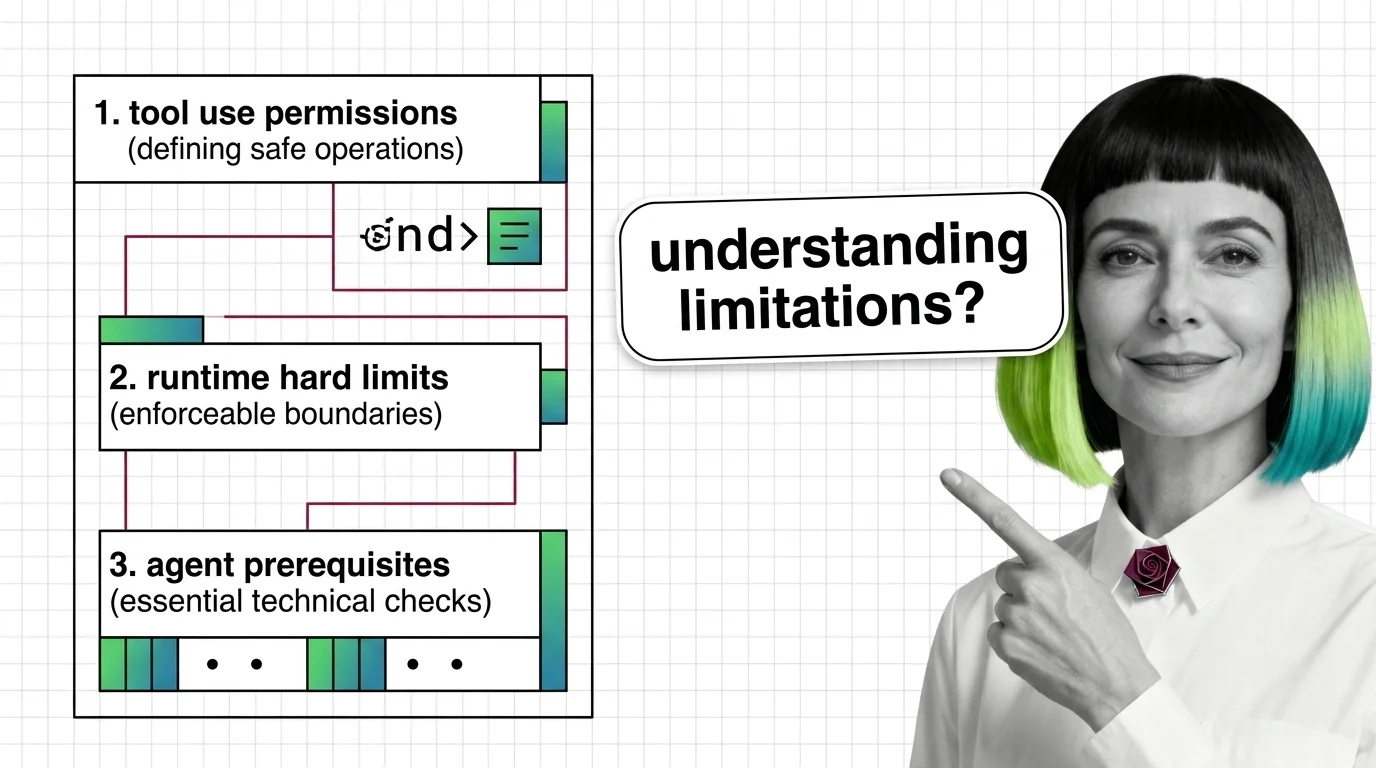
Agent guardrails are runtime classifiers wrapped around tool-use loops — useful, partial, and demonstrably evadable. Here's what to understand first.
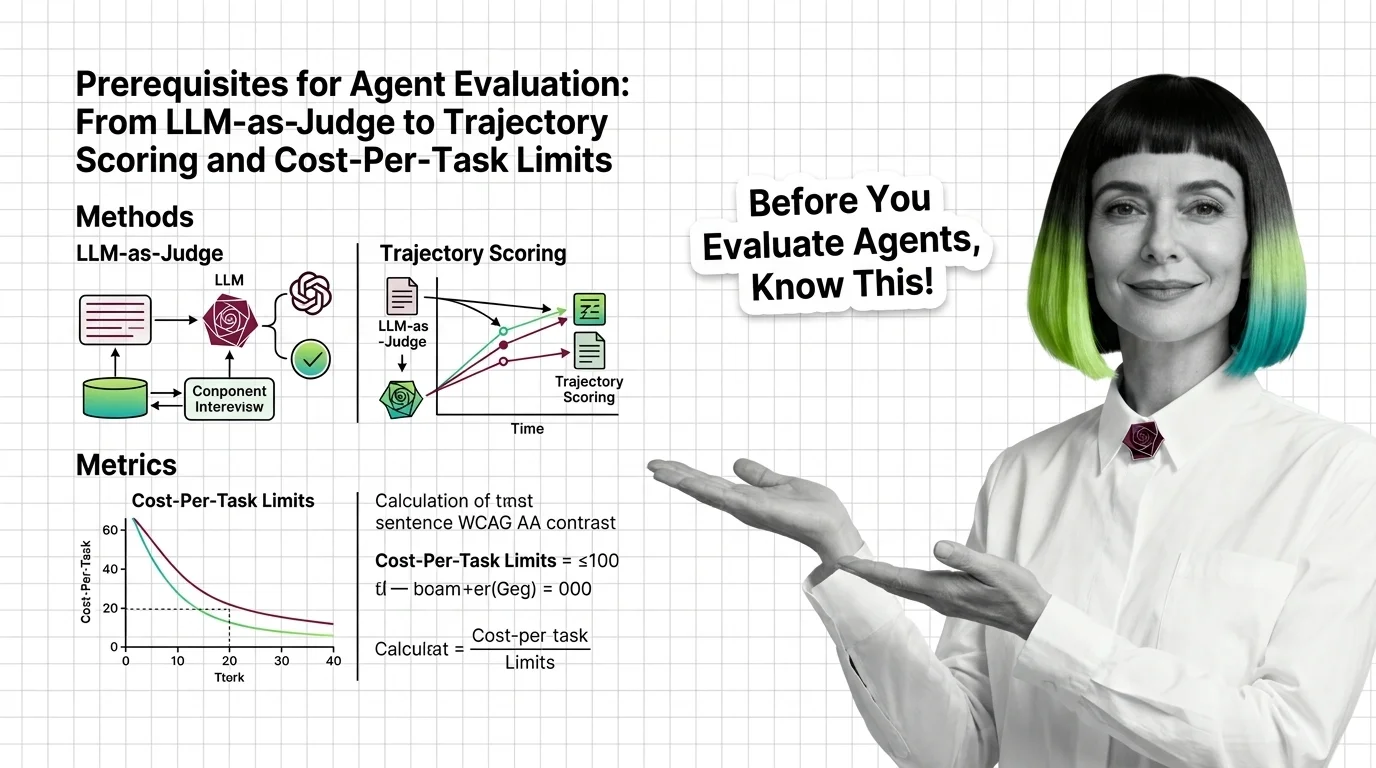
Agent evaluation needs three signals: outcome, trajectory, cost. Learn why LLM-as-judge has known biases and where major benchmarks quietly break.

Agent evaluation grades the path, not just the final answer. Learn how trajectory analysis exposes silent reasoning failures in production AI agents.