Explainer Articles
In-depth explanations of AI concepts, architectures, and principles. Educational content that breaks down complex topics into understandable insights.
- Home /
- Explainer Articles
Before Active Learning: Prerequisites, Building Blocks, and the Hard Limits of Query Strategies
Before Active Learning: Prerequisites, Building Blocks, and the Hard Limits of Query Strategies ELI5 …
Exact, Fuzzy, and Semantic Deduplication: The Components and Prerequisites of a Dedup Pipeline
Exact, Fuzzy, and Semantic Deduplication: The Components and Prerequisites of a Dedup Pipeline ELI5

False Positives, Lost Diversity, and the Technical Limits of Deduplicating Training Data
False Positives, Lost Diversity, and the Technical Limits of Deduplicating Training Data ELI5
Uncertainty Sampling Explained: Entropy, Margin, and Least-Confidence Query Strategies
Uncertainty Sampling Explained: Entropy, Margin, and Least-Confidence Query Strategies ELI5

What Is Active Learning and How Models Pick the Most Informative Samples to Label
What Is Active Learning and How Models Pick the Most Informative Samples to Label ELI5

What Is Data Deduplication and How MinHash LSH Detects Near-Duplicate Training Samples
What Is Data Deduplication and How MinHash LSH Detects Near-Duplicate Training Samples ELI5

Before You Preprocess: Data Types, Distributions, and Train-Test Splits You Need to Understand First
Before You Preprocess: Data Types, Distributions, and Train-Test Splits You Need to Understand First …

Data Leakage, Lost Information, and the Technical Limits of Preprocessing Pipelines
Data Leakage, Lost Information, and the Technical Limits of Preprocessing Pipelines ELI5
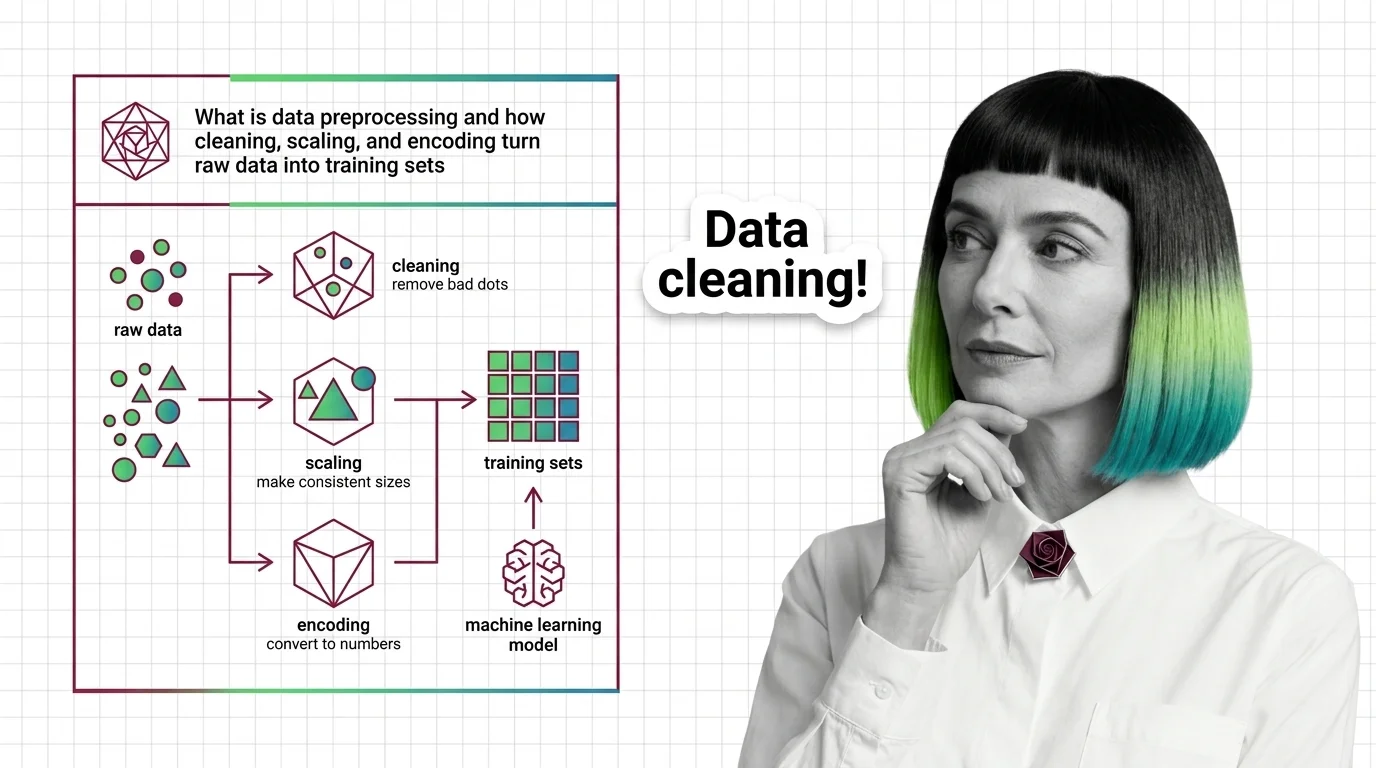
What Is Data Preprocessing and How Cleaning, Scaling, and Encoding Turn Raw Data into Training Sets
What Is Data Preprocessing and How Cleaning, Scaling, and Encoding Turn Raw Data into Training Sets …

Inter-Annotator Agreement, Annotation Guidelines, and the Building Blocks of a Labeling Project
Inter-Annotator Agreement, Annotation Guidelines, and the Building Blocks of a Labeling Project ELI5 …
Label Noise, Annotator Bias, and the Technical Limits of Human Data Annotation
Label Noise, Annotator Bias, and the Technical Limits of Human Data Annotation ELI5
What Is Data Augmentation and How Transforming Samples Expands Training Data
What Is Data Augmentation and How Transforming Samples Expands Training Data ELI5
What Is Data Labeling and Annotation, and How Ground-Truth Labels Train Supervised Models
What Is Data Labeling and Annotation, and How Ground-Truth Labels Train Supervised Models ELI5

When Data Augmentation Helps and When It Hurts: Distribution Shift and Label Corruption
When Data Augmentation Helps and When It Hurts: Distribution Shift and Label Corruption ELI5

Label Noise, Class Imbalance, and Distribution Shift: What to Know Before Fixing Training Data
Label Noise, Class Imbalance, and Distribution Shift: What to Know Before Fixing Training Data ELI5
What AI Technical-Debt Tools Actually Measure — and Where the Numbers Break
What AI Technical-Debt Tools Actually Measure — and Where the Numbers Break ELI5

What Is AI for Technical Debt and How Machine Learning Detects Code Smells and Hotspots
What Is AI for Technical Debt and How Machine Learning Detects Code Smells and Hotspots ELI5

What Is Training Data Quality and How It Determines Model Performance
What Is Training Data Quality and How It Determines Model Performance ELI5
Why Perfectly Clean Data Is Impossible: The Technical Limits of Data Curation at Scale
Why Perfectly Clean Data Is Impossible: The Technical Limits of Data Curation at Scale ELI5
Inside Code LLMs: Fill-in-the-Middle and the Training Data Behind Them
Inside Code LLMs: Fill-in-the-Middle and the Training Data Behind Them ELI5

Prerequisites and Technical Limits of AI in CI/CD: DevOps Foundations to Flaky-Test False Positives
Prerequisites and Technical Limits of AI in CI/CD: DevOps Foundations to Flaky-Test False Positives …
What Is AI in CI/CD Pipelines and How Automated Code Analysis and Deployment Checks Work
What Is AI in CI/CD Pipelines and How Automated Code Analysis and Deployment Checks Work ELI5
Context Window Collapse, Tool-Call Loops, and the Hard Technical Limits of Coding Agents in 2026
Context Window Collapse, Tool-Call Loops, and the Hard Technical Limits of Coding Agents in 2026 …
From Repo Indexing to Memory Files: Prerequisites and Limits of Code Context Engineering
From Repo Indexing to Memory Files: Prerequisites and Limits of Code Context Engineering ELI5

Prerequisites for Agentic Coding: Tool Use, Scaffolding, and the Plan-Execute-Verify Loop
Prerequisites for Agentic Coding: Tool Use, Scaffolding, and the Plan-Execute-Verify Loop ELI5

Prerequisites for Vibe Coding and the Technical Limits That Break the Illusion
Prerequisites for Vibe Coding and the Technical Limits That Break the Illusion ELI5

What Is Agentic Coding and How Plan-Write-Test-Iterate Loops Replace Manual Development
What Is Agentic Coding and How Plan-Write-Test-Iterate Loops Replace Manual Development ELI5
What Is Context Engineering for Code and How It Shapes AI Coding Assistant Output
What Is Context Engineering for Code and How It Shapes AI Coding Assistant Output ELI5